

Getting Started with ML
AWS Community Builder, AWS ML Specialist, Full-Stack Developer
Unfortunately, there is no standardised manual on how to execute ML. This is due to the fact that each ML use case is distinct and particular to the application that uses the resulting ML model. Instead, the majority of data scientists, ML engineers, and ML practitioners adhere to a broad workflow pattern. The Cross-Industry Standard Process for Data Mining (CRISP-DM) is a process model that was developed, and while not everyone adheres to the exact stages verbatim, most production ML models have probably been produced using the constraints that the CRISP-DM methodology offers. Therefore, when we talk about the ML process, we always mean the complete process of creating ML models that are ready for production while following the guidelines from CRSIP-DM.
An illustration of the CRISP-DM recommendations for designing a typical procedure that an ML practitioner might adhere to can be found in the graphic below:
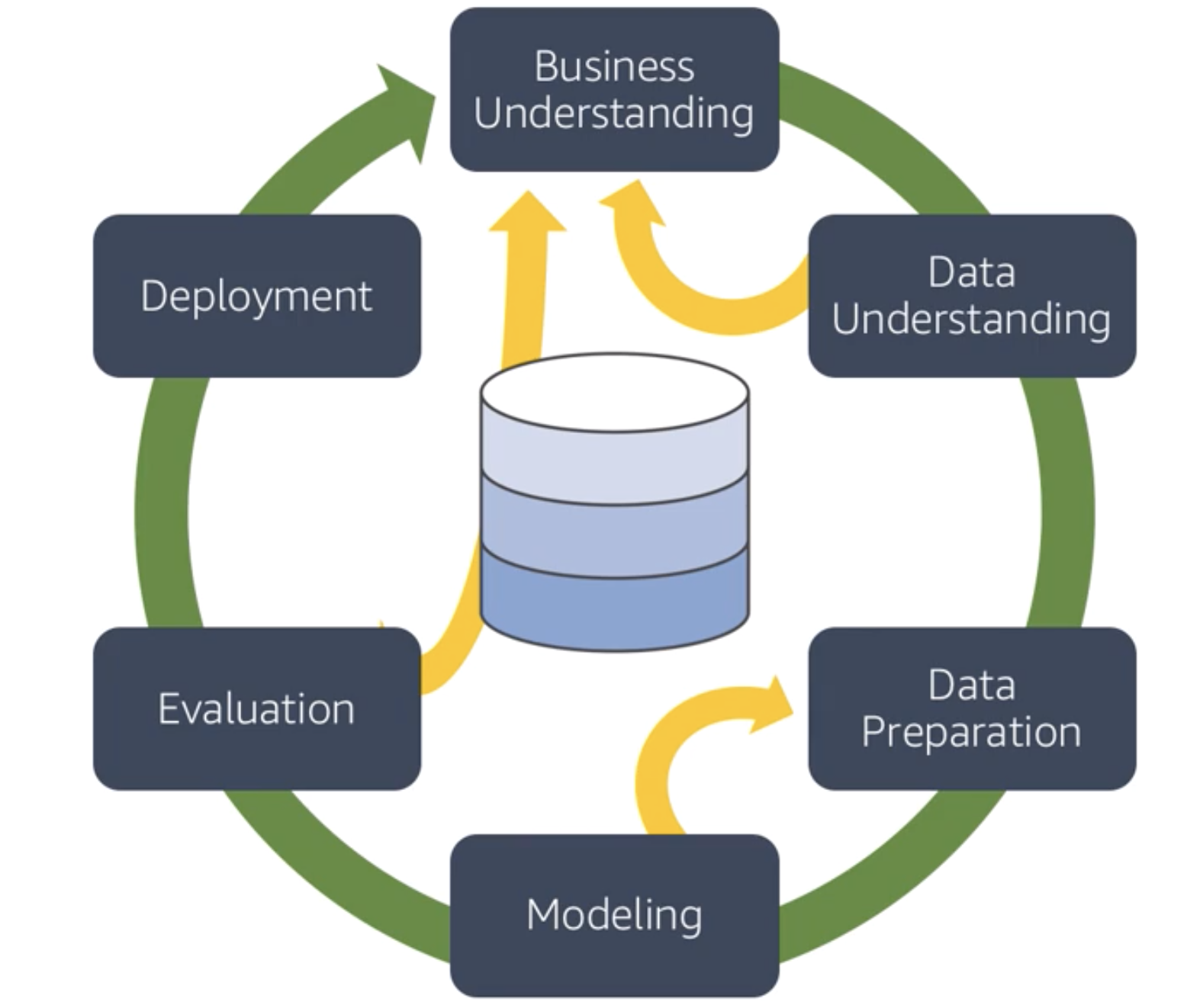
After the data has been reviewed, the ML practitioner decides which modelling techniques are most appropriate for addressing the use case and extracting the most pertinent information from the data. These methods consist of the following:
- Choosing the appropriate ML algorithm
- Adding additional elements to the data (engineering new features) that can raise the general efficacy of the selected model.
- Data separation into training and testing sets for model development and assessment
A model's suitability for use in production depends entirely on the quality of the data it was trained on. To extract the most pertinent features for model development and training, the data must be thoroughly evaluated and comprehended. Exploratory Data Analysis (EDA), which evaluates the statistical components of the data and may result in the creation of charts to better understand feature importance, can be used to achieve this. In order to help the trained model learn from these ideal properties, we may decide to collect additional vital data, delete uninteresting data, and maybe engineer new facets of the data.
In dealing with any problem, you have first do the following:
- Sourcing, ingesting, and understanding the data (EDA).
- Building the right model: In this stage, you have to select the most appropriate ML model / methodology to get the most accurate results / predictions.
Algorithms such as: • Linear regression • Support vector machines • Decision trees • Naïve Bayes • Neural networks
- Training the model:
- Evaluating the trained model We can proceed to the model evaluation stage of the ML process after the model has been trained. The trained model is now assessed against the goals and success criteria laid out in the business use case with the intention of determining whether or not the trained model is prepared for production. some metrics can be used for evaluation like RMSE.
Important different steps for ML engineer / practitioner to consider:
Use another model: It's important to take into account entails creating a brand-new model utilising a totally different method that nonetheless adheres to the use case. The ML expert might, for instance, do research using a different supervised learning, regression-based technique. Depending on the method, the data may also need to be reorganised to better match the needed input format.
Tuning the existing model Hence, this stage of the process is alsoreferred to as hyperparameter optimization (HPO).
Deploying the optimized model into production Insofar as some ML practitioners choose not to include this step in their ML process, model deployment is something of a murky area. For instance, some ML experts might believe that their only responsibility is to present a production-ready ML model that addresses the business use case. Once this model has been trained, it is simply given to the teams or owners who are responsible for developing the application so that they may test and incorporate the model into the application. To ensure that the trained model interacts properly with the application, some ML practitioners will collaborate with the application teams to deploy the model into a test or Quality Assurance (QA) environment.
Although the model deployment step in the accompanying diagram is when the CRISP-DM approach comes to an end, the process is actually ongoing. Once the model has been put into use in a production application, it needs to be closely watched to make sure it doesn't stray from its intended use and to guarantee that it regularly makes correct predictions on previously unknown or brand-new data. The ML practitioner will be required to restart the ML process in order to reoptimize the model and make it generalise to this new input should this circumstance emerge.