

Hugging Face's Transformers and Amazon SageMaker: A Serverless Inference


To develop a Serverless Inference endpoint, the Hugging Face Inference DLCs and Amazon SageMaker Python SDK will be used. A new feature in SageMaker called Amazon SageMaker Serverless Inference lets you scale and deploy machine learning models in a serverless environment. Similar to Amazon Lambda, serverless endpoints dynamically deploy compute resources and scale them up and down based on traffic. For workloads that can handle cold starts and have periods of inactivity in between traffic spikes, serverless inference is perfect. If your traffic is irregular or unpredictable, Serverless Inference with a pay-per-use model is a financially sensible choice.
That's how it works:
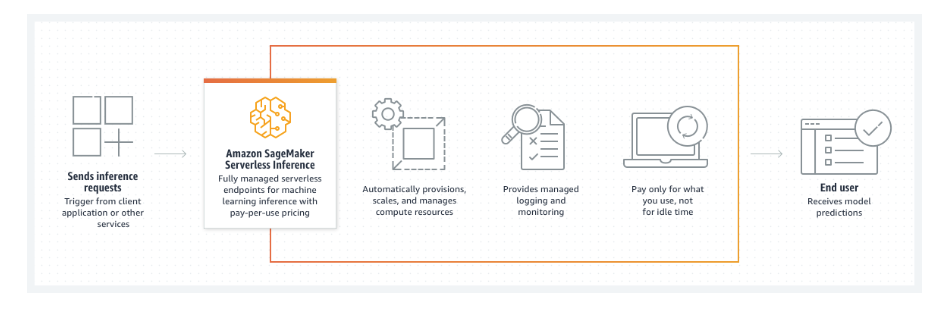
SageMaker controls the provisioning and management of the compute resources when you construct a serverless endpoint.
After that, you may ask the endpoint for inferences and get model predictions in return.
You only pay for what you use because SageMaker adjusts the computing resources up or down as necessary to handle the volume of your requests.
Let's begin writing some demo code:
import sagemaker
import boto3
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
Create Inference HuggingFaceModel for the Serverless Inference Endpoint
Our serverless endpoint runs on the distilbert-base-uncased-finetuned-sst-2-english model. This model is a DistilBERT-base-uncased fine-tune checkpoint tuned on SST-2 which is used for topic classification.
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.serverless import ServerlessInferenceConfig
# Hub Model configuration. <https://huggingface.co/models>
hub = {
'HF_MODEL_ID':'distilbert-base-uncased-finetuned-sst-2-english',
'HF_TASK':'text-classification'
}
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
env=hub, # configuration for loading model from Hub
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version='py38', # python version used
)
# Specify MemorySizeInMB and MaxConcurrency in the serverless config object
serverless_config = ServerlessInferenceConfig(
memory_size_in_mb=4096, max_concurrency=10,
)
# deploy the endpoint endpoint
predictor = huggingface_model.deploy(
serverless_inference_config=serverless_config
)
An HuggingFacePredictor object that can be used to request inference is returned by the.deploy() method. It's simple to submit queries to your endpoint and receive responses thanks to this HuggingFacePredictor.
data = {
"inputs": "the mesmerizing performances of the leads keep the film grounded and keep the audience riveted .",
}
res = predictor.predict(data=data)
print(res)
Clean up
predictor.delete_model()
predictor.delete_endpoint()